AI News
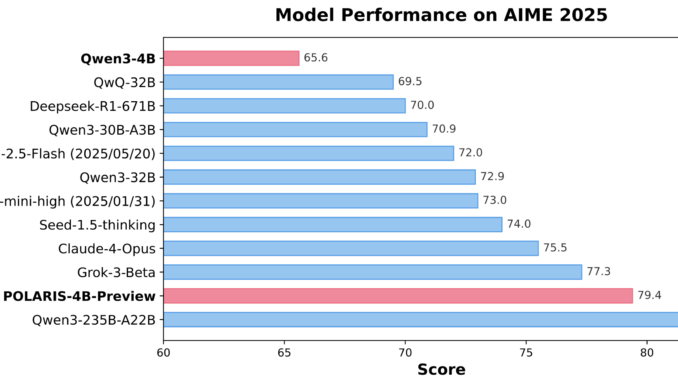
Polaris-4B and Polaris-7B: Post-Training Reinforcement Learning for Efficient Math and Logic Reasoning
The Rising Need for Scalable Reasoning Models in Machine Intelligence Advanced reasoning models are at the frontier of machine intelligence, especially in domains like math problem-solving and symbolic reasoning. These models are designed to perform […]